Background Information
Overview
Proper host tuning can lead to up to 100x performance increases.
Here are the reasons why.
TCP Buffer Sizing
TCP uses what is called the "congestion window", or CWND, to determine how many packets can be sent at one time. The larger the congestion window size, the higher the throughput. The TCP "slow start" and "congestion avoidance" algorithms determine the size of the congestion window. The maximum congestion window is related to the amount of buffer space that the kernel allocates for each socket. For each socket, there is a default value for the buffer size, which can be changed by the program using a system library call just before opening the socket. There is also a kernel enforced maximum buffer size. The buffer size can be adjusted for both the send and receive ends of the socket.
To get maximal throughput it is critical to use optimal TCP send and receive socket buffer sizes for the link you are using. If the buffers are too small, the TCP congestion window will never fully open up. If the receiver buffers are too large, TCP flow control breaks and the sender can overrun the receiver, which will cause the TCP window to shut down. This is likely to happen if the sending host is faster than the receiving host. Overly large windows on the sending side is not usually a problem as long as you have excess memory; note that every TCP socket has the potential to request this amount of memory even for short connections, making it easy to exhaust system resources.
The optimal buffer size is twice the bandwidth*delay product (see also a helpful BDP calculator) of the link:
buffer size = 2 * bandwidth * delay
The ping program can be used to get the delay. Determining the end-to-end capacity (the bandwidth of the slowest hop in your path) is trickier, and may require you to ask around to find out the capacity of various networks in the path. Since ping gives the round trip time (RTT), this formula can be used instead of the previous one:
buffer size = bandwidth * RTT
For example, if your ping time is 50 ms, and the end-to-end network consists of all 1G or 10G Ethernet, the TCP buffers should be:
.05 sec * (1 Gbit / 8 bits) = 6.25 MBytes.
Historically in order get full bandwidth required the the user to specify the buffer size for the network path being used, and the the application programmer had to set use the SO_SNDBUF and SO_RCVBUF options of the BSD setsockopt() call to set the buffer size for the sender an receiver. Luckily Linux, FreeBSD, Windows, and Mac OSX all now support TCP autotuning, so you no longer need to worry about setting the default buffer sizes.
TCP Autotuning
Beginning with Linux 2.6 (released in 2005), Mac OSX 10.5, Windows Vista, and FreeBSD 7.0, both sender and receiver autotuning became available, eliminating the need to set the TCP send and receive buffers by hand for each path. However the maximum buffer sizes are still too small for many high-speed network path, and must be increased as described on the pages for each operating system.
TCP Autotuning Maximum
Adjusting the default maximum Linux TCP buffer sizes allows the autotuning algorithms the ability to scale the sending and receiving window to take advantage of available bandwidth on long paths. Each operating system reacts to this setting differently, please see operating system specific resources on recommendations.
The following graph illustrates the impact of increasing the maximum TCP buffer size on two Linux servers that are separated by a 75ms round trip path. The value was adjusted from 32MB to 64MB, and resulted in a throughput improvement of nearly 2X.
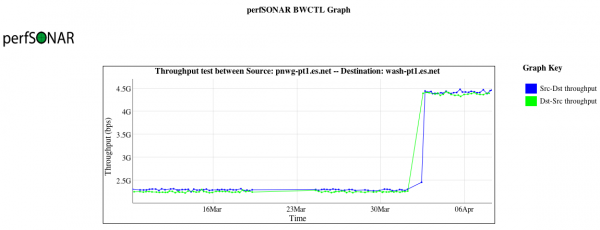
ESnet recommends sensible defaults for this value, typically between 32MB and 128MB. An expectation of 10Gbps, single stream, across a path of 100ms, will require a 120MB buffer, baring any network loss. Hosts that have an expectation of faster speeds or longer distances will need more. Those intending to use parallel streams should use less to avoid memory exhaustion.
TCP Congestion Avoidance Algorithms
The TCP reno congestion avoidance algorithm was the default in all TCP implementations for many years. However, as networks got faster and faster it became clear that reno would not scale well for high bandwidth delay product networks. To address this a number of new congestion avoidance algorithms were developed, including CUBIC, HTCP, and BBR. Most Linux distributions use cubic by default, which became the default in kernel 2.6.19, released in 2006. More details on can be found at: http://en.wikipedia.org/wiki/TCP_congestion_avoidance_algorithm